About Me
Hi, I am Xu Wan (万旭). I am currently a researcher in the ByteDance Seed Team. I received my Ph.D. from the College of Control Science and Engineering at Zhejiang University in June 2026. I was previously a visiting student at the IDEAL Lab, Peking University, advised by Prof. Mingyang Sun. During my Ph.D., I interned at Tencent Hunyuan, ByteDance Seed, Alibaba DAMO Academy, and NetEase Fuxi AI Lab, and had the pleasure of collaborating with Prof. Wotao Yin, Dr. Speed Zhu, Dr. Yansheng Wang, Dr. Yujing Hu, and many other outstanding researchers.
Research vision
Learning in Constraint Spaces
My research asks a central question: how can intelligent systems learn to reason and act when computation, feedback, and physical rules are limited? I view constraints not merely as obstacles, but as useful structure for building intelligence that is more efficient, reliable, and deployable.
Reason where it matters.
Learn from imperfect signals.
Act within the world that exists.
Together, these threads explore how limited resources and hard rules can become design signals for better intelligence.
Across these directions, I have published first-author work at NeurIPS, ICML, and ICLR, as well as in journals such as IEEE Transactions on Power Systems.

Beyond research, I am passionate about fitness and enjoy running and strength training. You can follow my training journey on my Strava profile. I am also enthusiastic about trail running and hiking.
A year in motion
News
- 2026.05: 🎉🎉 Three papers about LLM Token Allocation / LLM for Optimization / T2I RL post-train got accepted at ICML 2026!
- 2026.03: 🎉🎉 One paper about Length Penalty of LLM got accepted at ACL 2026!
- 2026.01: 🎉🎉 One paper about Off-policy LLM-RL post-train got accepted at ICLR 2026 (first author)!
- 2025.09: 🎉🎉 One paper about robust safe RL got accepted at NeurIPS 2025 (first author)!
- 2025.07: 🎉🎉 I was supported by the CIE-Tencent Doctoral Research Incentive Project (with only 23 recipients nationwide and a research fund of 100,000 RMB)!
- 2025.05: 🎉🎉 One paper about elastic cloud service got accepted at SIGKDD 2025 (co-first author)!
- 2025.05: 🎉🎉 One paper about LLM and RL colloboratation got accepted at ICML 2025 (first author)!
- 2024.12: 🎉🎉 One paper about multi-agent RL got accepted as an oral presentation at AAAI 2025 (first author)!
Publications
Spotlight Publications
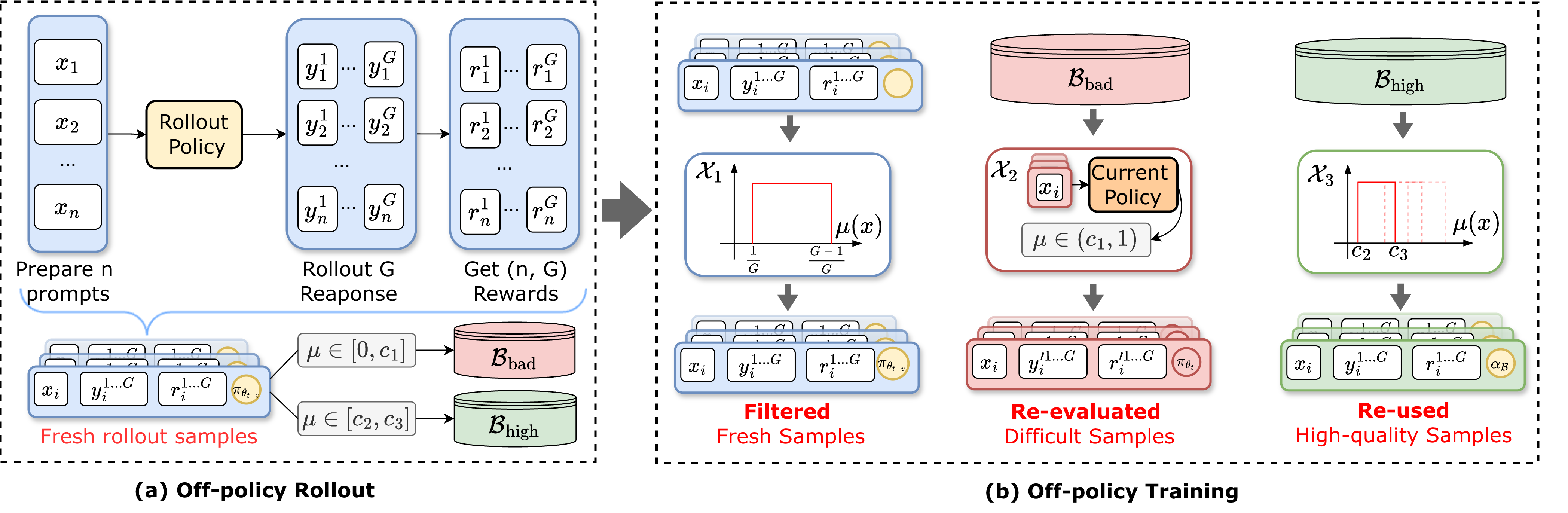
Buffer Matters: Unleashing the Power of Off-Policy Reinforcement Learning in Large Language Model Reasoning [Code]
Xu Wan, Yansheng Wang, Wenqi Huang, Mingyang Sun
- BAPO is an off-policy RLVR framework to improve the data efficiency in large language models post-training.
The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs [Code]
Xu Wan, SpeedZhu, Jiawei Cai, Guang Chen, Ximing Huang, Wiggin Zhou, Mingyang Sun
- CLEAR implements a Lambert W policy to execute strategic abandonment, sacrificing insolvent tasks to redistribute critical computational resources to solvable complex queries.
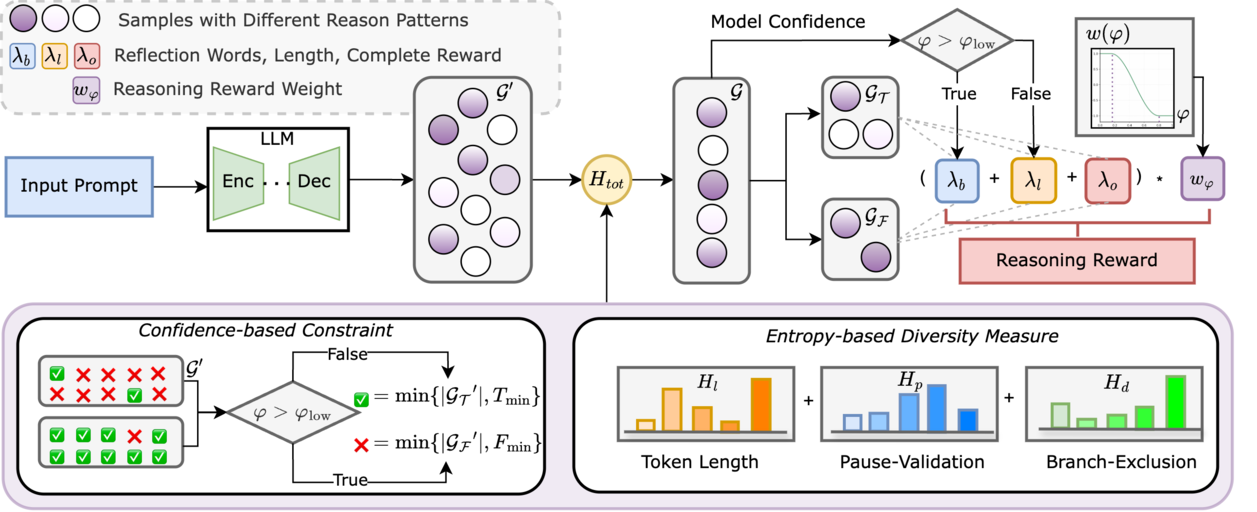
AdapThink: Adaptive Thinking Preferences for Reasoning Language Model [Code]
Wenyue Xu*, Xu Wan*(co-first author), Wei Wang, Wotao Yin, Wenqi Huang, Shengjie Zhao, Mingyang Sun
- AdapThink is an adaptive length penalty method for efficient thinking of reasoning language models.
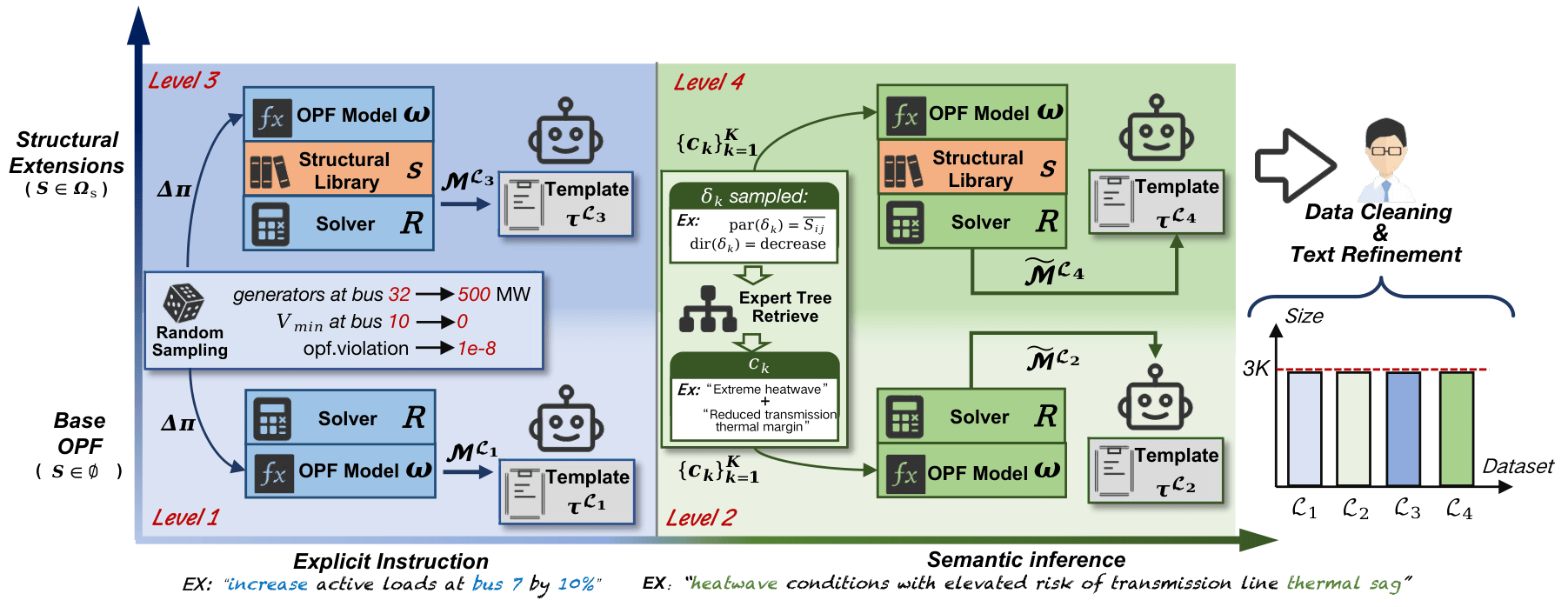
ProOPF: Benchmarking and Improving LLMs for Professional-Grade Power Systems Optimization Modeling [Code]
Chao Shen, Zihan Guo, Xu Wan*(co-first author), Zhenghao Yang, Yifan Zhang, Wengi Huang, Jie Song, Zongyan Zhang, Mingyang Sun
- ProOPF introduces a 12K-instance dataset and a 121-case expert benchmark for evaluating and improving LLMs on professional-grade optimal power flow modeling from natural language.

Think Twice, Act Once: A Co-Evolution Framework of LLM and RL for Large-Scale Decision Making
Xu Wan, Wenyue Xu, Chao Yang, Mingyang Sun
- Agents Co-Evolution (ACE) is a synergistic framework between LLMs and RL agents for large-scale decision-making scenarios.
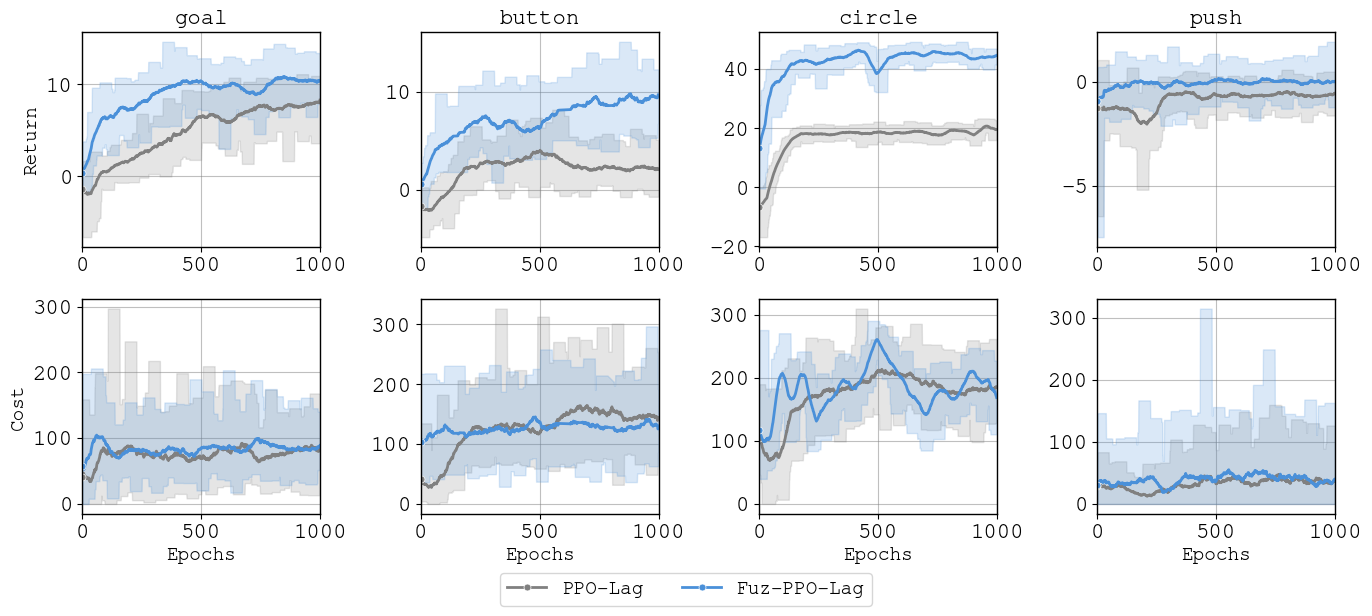
Fuz-RL: A Fuzzy-Guided Robust Framework for Safe Reinforcement Learning under Uncertainty [Code]
Xu Wan, Chao Yang, Cheng Yang, Jie Song, Mingyang Sun
- Fuz-RL is a novel fuzzy-guided robust framework for safe RL.
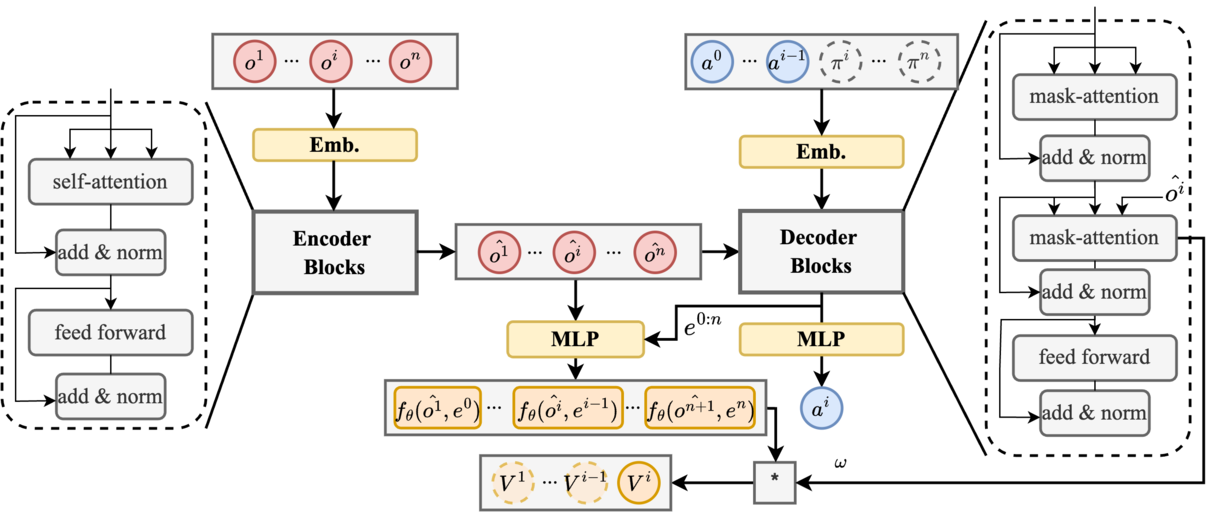
SrSv: Integrating Sequential Rollouts with Sequential Value Estimation for Multi-agent Reinforcement Learning [Code]
Xu Wan, Chao Yang, Cheng Yang, Jie Song, Mingyang Sun
- SrSv aims to capture agent interdependence and provide a scalable solution for cooperative MARL.
Full Publications
* denotes co-first authors, # denotes corresponding author.
Under Review
- SAMG: Offline-to-Online Reinforcement Learning via State-Action-Conditional Offline Model Guidance, Liyu Zhang, Xu Wan, Haochi Wu, Quan Kong, Ruilong Deng, Mingyang Sun, Under Review
2026
- The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs, Xu Wan*, SpeedZhu*, Jiawei Cai, Guang Chen, Ximing Huang, Wiggin Zhou, Mingyang Sun,ICML 2026 [Code]
- ProOPF: Benchmarking and Improving LLMs for Professional-Grade Power Systems Optimization Modeling, Chao Shen*, Zihan Guo*, Xu Wan*, Zhenghao Yang, Yifan Zhang, Wengi Huang, Jie Song, Zongyan Zhang, Mingyang Sun, ICML 2026 [Code]
- Principled RL for Flow Matching Emerges From the Chunk-level Policy Optimization, Yifu Luo, Haoyuan Sun, Xinhao Hu, Xu Wan, et.al, ICML 2026 [Code]
- AdapThink: Adaptive Thinking Preferences for Reasoning Language Model, Wenyue Xu, Xu Wan, Wei Wang, Wotao Yin, Wenqi Huang, Shengjie Zhao, Mingyang Sun, ACL 2026 (Findings) [Code]
- Buffer Matters, Unleashing the Power of Off-Policy Reinforcement Learning in Large Language Model Reasoning, Xu Wan, Yansheng Wang, Wenqi Huang, Mingyang Sun, ICLR 2026 [Code]
2025
- Fuz-RL: A Fuzzy-Guided Robust Framework for Safe Reinforcement Learning under Uncertainty, Xu Wan, Chao Yang, Cheng Yang, Jie Song, Mingyang Sun, NeurIPS 2025 [Code]
- IVMR suite: An Industrial-scale Virtual Machine Rescheduling Dataset and Benchmark for Elastic Cloud Service, Yupeng Zhang*, Xu Wan*, Xiangyun Kong*, Chao Yang, Binda Ma, Wotao Yin, Jian Zhou, SIGKDD 2025 [Code]
- Think Twice, Act Once: A Co-Evolution Framework of LLM and RL for Large-Scale Decision Making, Xu Wan, Wenyue Xu, Chao Yang, Mingyang Sun, ICML 2025
2024
- SrSv: Integrating Sequential Rollouts with Sequential Value Estimation for Multi-agent Reinforcement Learning, Xu Wan, Wenyue Xu, Chao Yang, Mingyang Sun, AAAI 2025 (Oral) [Code]
- AdapSafe2: Prior-Free Safe-Certified Reinforcement Learning for Multi-Area Frequency Control, Xu Wan, Mingyang Sun, IEEE Trans. Power System
2023
- Highly Transferable Adversarial Attack Against Deep-Reinforcement-Learning-Based Frequency Control, Zhongwei Li, Yang Liu, Peng Qiu, Hongyan Yin, Xu Wan #, Mingyang Sun, Energy Convers. Econ
- AdapSafe: Adaptive and Safe-Certified Deep Reinforcement Learning-Based Frequency Control for Carbon-neutral Power Systems, Xu Wan, Mingyang Sun, Boli Chen, Zhongda Chu, Fei Teng, AAAI 2023 [Code]
2022 and Prior
- Physics-Constrained Vulnerability Assessment of Deep Reinforcement Learning-Based SCOPF, Lanting Zen, Mingyang Sun, Xu Wan, Zhenyong Zhang, Ruilong Deng, Yan Xu, IEEE Trans. Power System
- Exploring the Vulnerability of Deep Reinforcement Learning-based Emergency Control for Low Carbon Power Systems, Xu Wan, Lanting Zen, Mingyang Sun, IJCAI 2022 [Code]
Honors and Awards
- 2026.06: Sun Youxian Academician Scholarship (孙优贤院士奖学金), awarded to only 5 Ph.D. students university-wide, with a RMB 30,000 scholarship
- 2025.07: Named a Hunyuan Scholar (混元学者), with RMB 100,000 in project funding
- 2023.10: China Optics Valley Scholarship (中国光谷奖学金), with a RMB 10,000 scholarship
- 2022.11: First Prize in the 4th China Graduate Student Artificial Intelligence Innovation Competition (Huawei Cup), Top 6 Nationally, with a RMB 30,000 cash award
- 2022.10: Second Prize in Baidu PaddlePaddle China University Computer Competition, Top 8 Nationally, with a RMB 10,000 cash award
- 2022.10: National Scholarship for Graduate Students
- 2022.08: First Prize in the 3rd National College Student Mathematical Modeling Competition (Huashu Cup), Top 5% Nationally
- 2020.04: First Prize in American Mathematical Contest in Modeling (MCM), Top 7.4% Globally
- 2019.10: National Scholarship for Undergraduate Students
Services
-
Reviewer for ICML 2026
-
Reviewer for ICLR 2026
-
Reviewer for NeurIPS 2025
-
Reviewer for TPWRS (Transactions on Power System)
-
Program Committee for AAAI 2026 (Main Track and AIA track)
Visitors
Visitors by country · total page views · since July 20, 2026