
Hi, I am Xu Wan (万旭), a third-year PhD student at the College of Control Science and Engineering, Zhejiang University, and currently serves as a visiting student at the IDEAL Lab of Peking University under the supervision of Prof. Mingyang Sun. During my graduate studies, I have gained valuable research experience as a research intern at ByteDance Seed Robotics Team, Alibaba DAMO Academy, and NetEase Fuxi AI Lab, collaborating with Prof. Wotao Yin, Dr. Yansheng Wang, and Dr. Yujing Hu. I am currently an intern with Tecent Hunyuan team.
My research interests include large language models (LLMs), reinforcement learning (RL), and large-scale AI applications, with a special focus on LLM post-training. I’ve published several first-author papers at international AI conferences like NeurIPS, ICML, ICLR, KDD, and AAAI, as well as in journals such as IEEE Transactions on Power Systems with google citations

Beyond research, I am passionate about fitness and enjoys running and strength training. You can follow my training journey on my Strava profile. I am also enthusiastic about trail running and hiking.
🔥 News
- 2026.01: 🎉🎉 One paper about LLM RL got accepted at ICLR 2026 (first author)!
- 2025.09: 🎉🎉 One paper about robust safe RL got accepted at NeurIPS 2025 (first author)!
- 2025.07: 🎉🎉 I was supported by the CIE-Tencent Doctoral Research Incentive Project (with only 23 recipients nationwide and a research fund of 100,000 RMB)!
- 2025.05: 🎉🎉 One paper about elastic cloud service got accepted at SIGKDD 2025 (co-first author)!
- 2025.05: 🎉🎉 One paper about LLM and RL colloboratation got accepted at ICML 2025 (first author)!
- 2024.12: 🎉🎉 One paper about multi-agent RL got accepted as an oral presentation at AAAI 2025 (first author)!
📝 Publications
🍾 Spotlight Publications
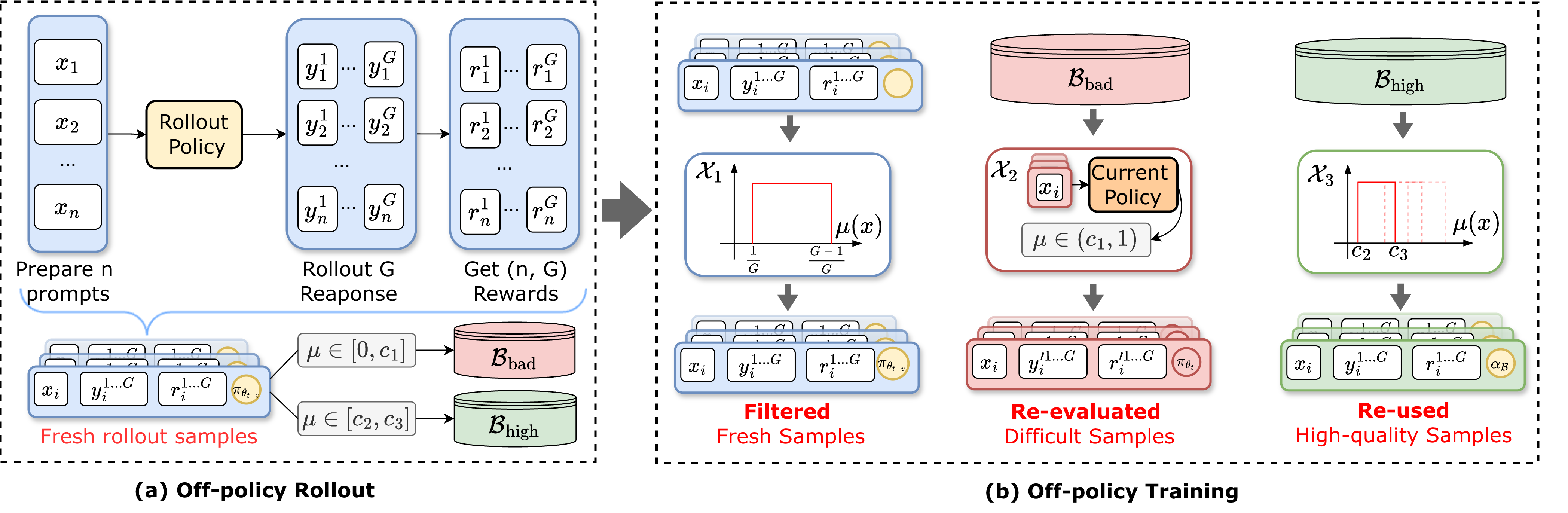
Xu Wan, Chao Yang, Yansheng Wang, Wenqi Huang, Mingyang Sun
- BAPO is an off-policy RLVR framework to improve the data efficiency in large language models post-training.
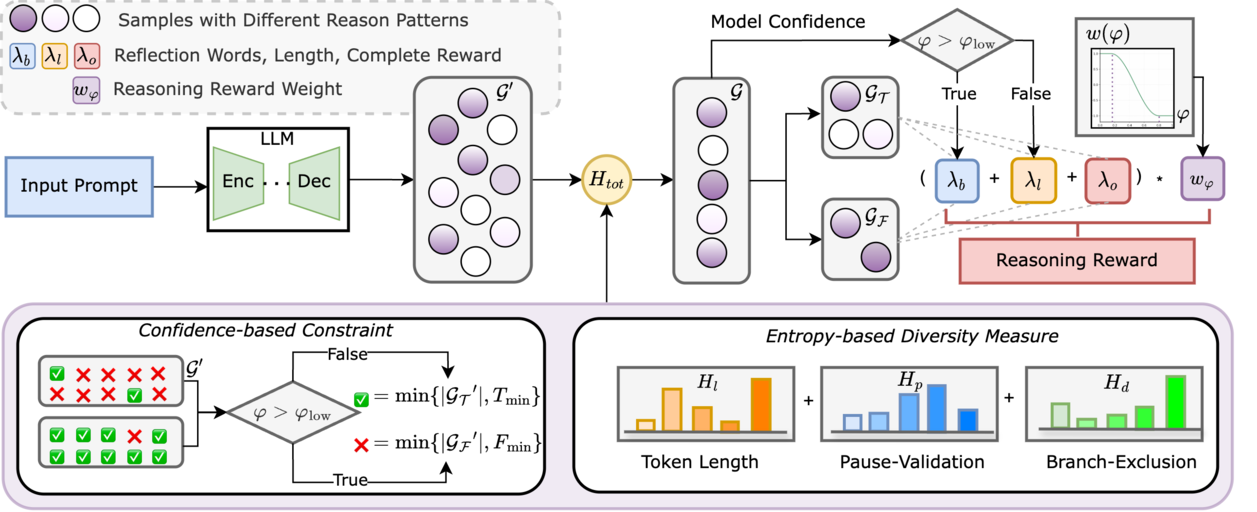
AdapThink: Adaptive Thinking Preferences for Reasoning Language Model
Xu Wan, Wei Wang, Wenyue Xu, Wotao Yin, Jie Song, Mingyang Sun
- AdapThink is an adaptive length penalty method for efficient thinking of reasoning language models.
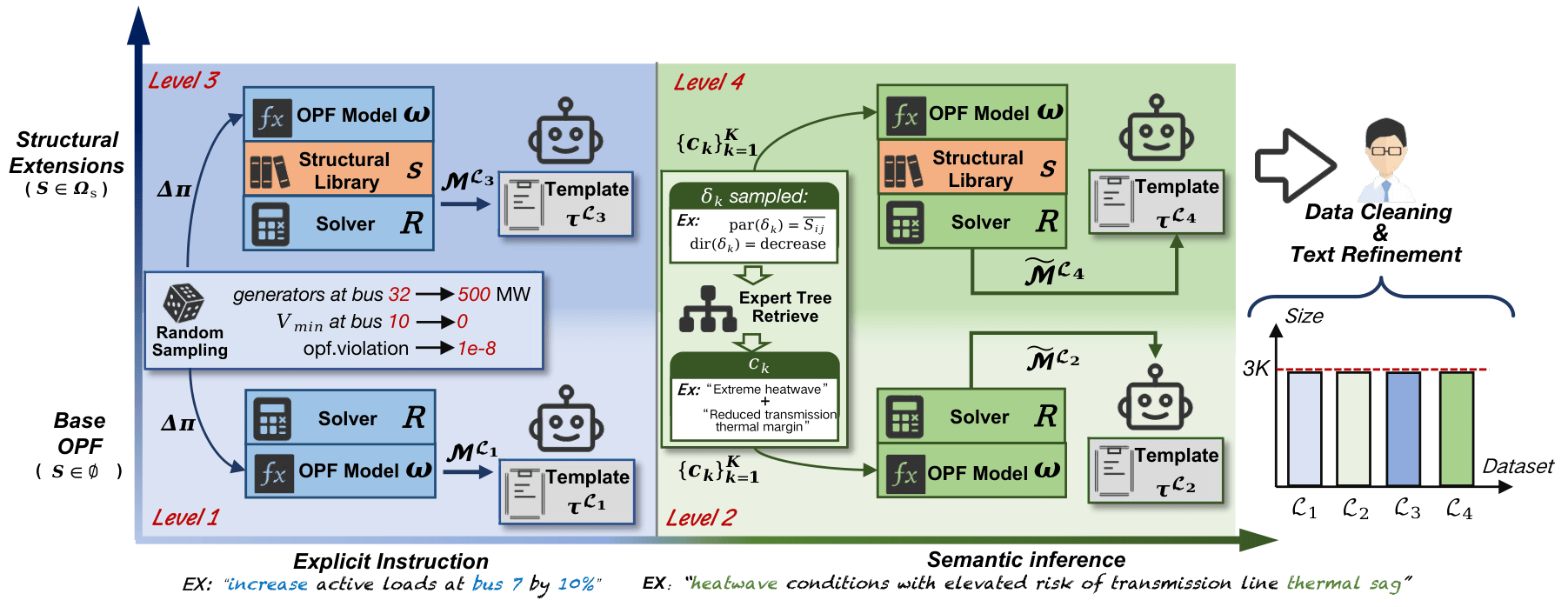
ProOPF: Benchmarking and Improving LLMs for Professional-Grade Power Systems Optimization Modeling
Chao Shen, Zihan Guo, Xu Wan*(co-first author), Zhenghao Yang, Yifan Zhang, Wengi Huang, Jie Song, Zongyan Zhang, Mingyang Sun
- ProOPF introduces a 12K-instance dataset and a 121-case expert benchmark for evaluating and improving LLMs on professional-grade optimal power flow modeling from natural language.
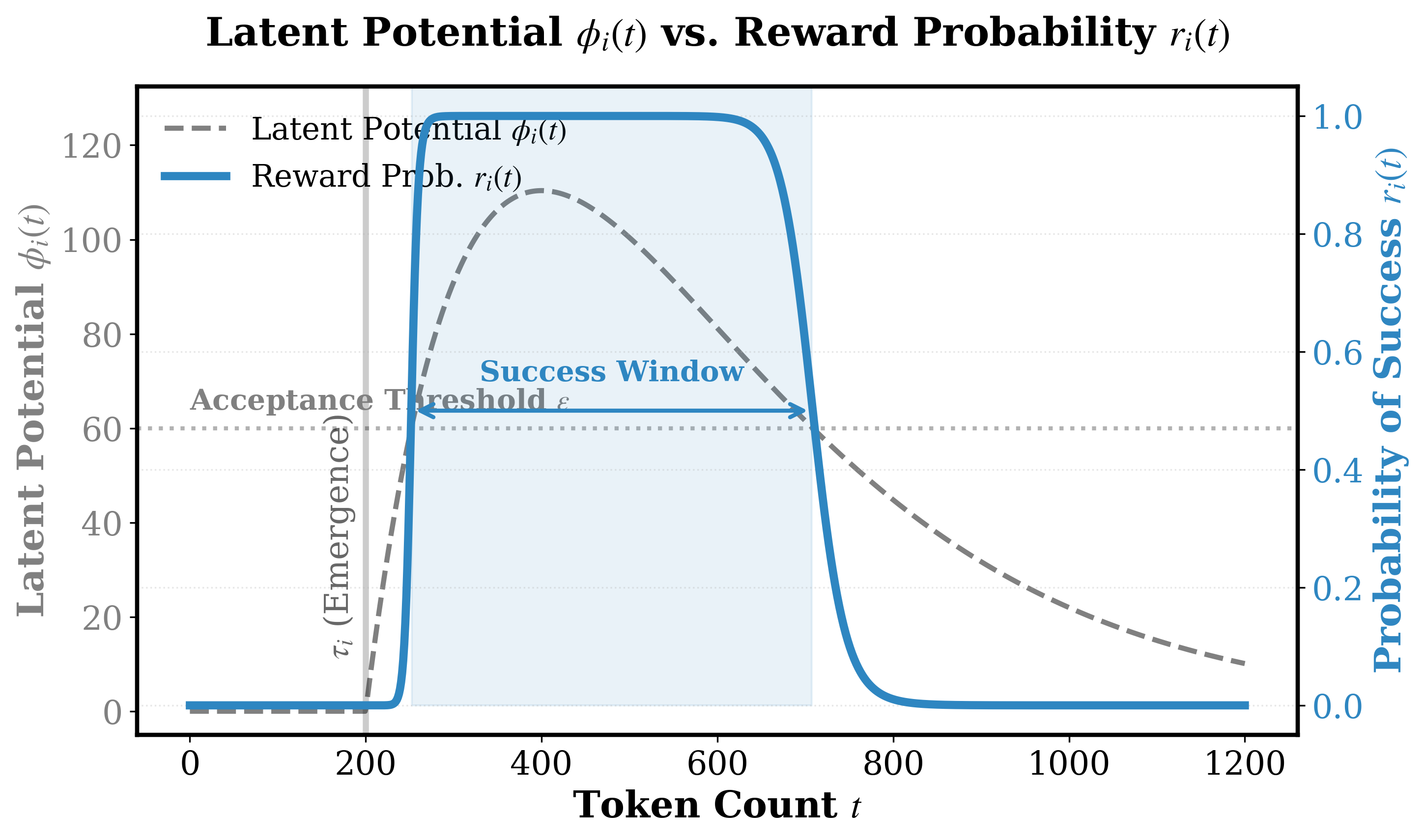
The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
Xu Wan, SpeedZhu, Jiawei Cai, Guang Chen, Ximing Huang, Wiggin Zhou, Mingyang Sun
- DABA implements a Lambert W policy to execute strategic abandonment, sacrificing insolvent tasks to redistribute critical computational resources to solvable complex queries.

Think Twice, Act Once: A Co-Evolution Framework of LLM and RL for Large-Scale Decision Making
Xu Wan, Wenyue Xu, Chao Yang, Mingyang Sun
- Agents Co-Evolution (ACE) is a synergistic framework between LLMs and RL agents for large-scale decision-making scenarios.
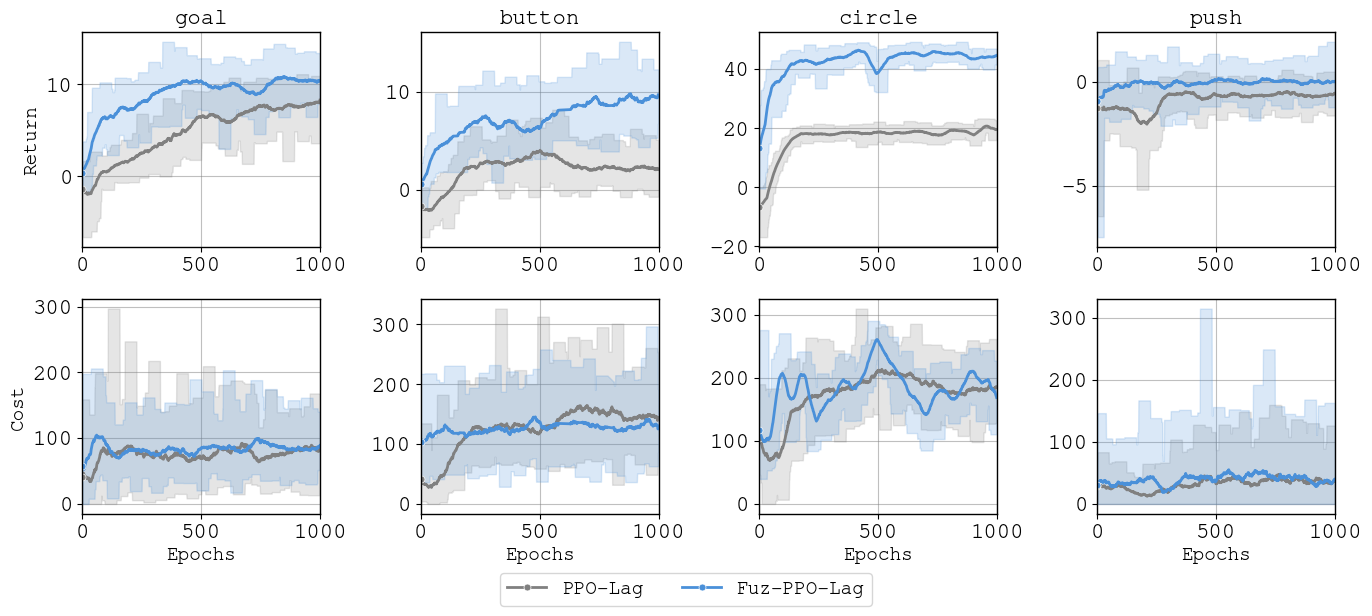
Fuz-RL: A Fuzzy-Guided Robust Framework for Safe Reinforcement Learning under Uncertainty
Xu Wan, Chao Yang, Cheng Yang, Jie Song, Mingyang Sun
- Fuz-RL is a novel fuzzy-guided robust framework for safe RL.
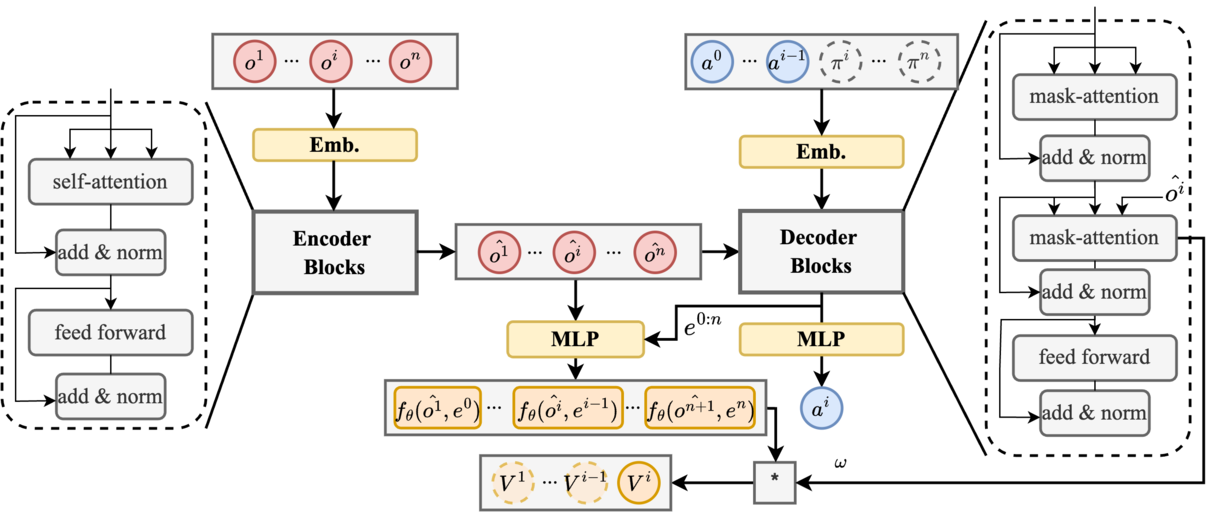
Xu Wan, Chao Yang, Cheng Yang, Jie Song, Mingyang Sun
- SrSv aims to capture agent interdependence and provide a scalable solution for cooperative MARL.
📖 Full Publications
* denotes co-first authors, # denotes corresponding author.
Under Review
- The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs, Xu Wan*, SpeedZhu*, Jiawei Cai, Guang Chen, Ximing Huang, Wiggin Zhou, Mingyang Sun,Under Review
- ProOPF: Benchmarking and Improving LLMs for Professional-Grade Power Systems Optimization Modeling, Chao Shen*, Zihan Guo*, Xu Wan*, Zhenghao Yang, Yifan Zhang, Wengi Huang, Jie Song, Zongyan Zhang, Mingyang Sun, Under Review
- AdapThink: Adaptive Thinking Preferences for Reasoning Language Model, Xu Wan, Wei Wang, Wenyue Xu, Wotao Yin, Jie Song, Mingyang Sun, Under Review
- SAMG: Offline-to-Online Reinforcement Learning via State-Action-Conditional Offline Model Guidance, Liyu Zhang, Xu Wan, Haochi Wu, Quan Kong, Ruilong Deng, Mingyang Sun, Under Review
2026
- Buffer Matters, Unleashing the Power of Off-Policy Reinforcement Learning in Large Language Model Reasoning, Xu Wan, Yansheng Wang, Wenqi Huang, Mingyang Sun, ICLR 2026
2025
- Fuz-RL: A Fuzzy-Guided Robust Framework for Safe Reinforcement Learning under Uncertainty, Xu Wan, Chao Yang, Cheng Yang, Jie Song, Mingyang Sun, NeurIPS 2025 [Code]
- IVMR suite: An Industrial-scale Virtual Machine Rescheduling Dataset and Benchmark for Elastic Cloud Service, Yupeng Zhang*, Xu Wan*, Xiangyun Kong*, Chao Yang, Binda Ma, Wotao Yin, Jian Zhou, SIGKDD 2025 [Code]
- Think Twice, Act Once: A Co-Evolution Framework of LLM and RL for Large-Scale Decision Making, Xu Wan, Wenyue Xu, Chao Yang, Mingyang Sun, ICML 2025
2024
- SrSv: Integrating Sequential Rollouts with Sequential Value Estimation for Multi-agent Reinforcement Learning, Xu Wan, Wenyue Xu, Chao Yang, Mingyang Sun, AAAI 2025 (Oral) [Code]
- AdapSafe2: Prior-Free Safe-Certified Reinforcement Learning for Multi-Area Frequency Control, Xu Wan, Mingyang Sun, IEEE Trans. Power System
2023
- Highly Transferable Adversarial Attack Against Deep-Reinforcement-Learning-Based Frequency Control, Zhongwei Li, Yang Liu, Peng Qiu, Hongyan Yin, Xu Wan #, Mingyang Sun, Energy Convers. Econ
- AdapSafe: Adaptive and Safe-Certified Deep Reinforcement Learning-Based Frequency Control for Carbon-neutral Power Systems, Xu Wan, Mingyang Sun, Boli Chen, Zhongda Chu, Fei Teng, AAAI 2023 [Code]
2022 and Prior
- Physics-Constrained Vulnerability Assessment of Deep Reinforcement Learning-Based SCOPF, Lanting Zen, Mingyang Sun, Xu Wan, Zhenyong Zhang, Ruilong Deng, Yan Xu, IEEE Trans. Power System
- Exploring the Vulnerability of Deep Reinforcement Learning-based Emergency Control for Low Carbon Power Systems, Xu Wan, Lanting Zen, Mingyang Sun, IJCAI 2022 [Code]
🎖 Honors and Awards
- 2022.11: First Prize in the 4th China Graduate Student Artificial Intelligence Innovation Competition (Huawei Cup), Top 6 Nationally
- 2022.08: First Prize in the 3rd National College Student Mathematical Modeling Competition (Huashu Cup), Top 5% Nationally
- 2020.04: First Prize in American Mathematical Contest in Modeling (MCM), Top 7.4% Globally
- 2022.10: Second Prize in Baidu PaddlePaddle China University Computer Competition, Top 8 Nationally
- 2022.05: Second Prize in MathorCup College Student Mathematical Modeling Challenge, Top 15% Nationally
- 2021.11: Second Prize in the 19th China Graduate Student Mathematical Modeling Competition, Top 15% Nationally
👨💼 Services
-
Reviewer for ICML 2026
-
Reviewer for ICLR 2026
-
Reviewer for NeurIPS 2025
-
Reviewer for TPWRS (Transactions on Power System)
-
Program Committee for AAAI 2026 (Main Track and AIA track)